
IDE For LLMs
Build, Fine-tune and Deploy like never beforeEngineering
The Evolution of Data Science Environments: From Jupyter to the Future
An analysis of the history of notebooks, how they entered into the corporate world and a look to the future
Written by: Greg Michaelson , February 29, 2024

Content of the article:
- Introduction to Notebooks
- Transition from Academia to Business
- Evolution within the Corporate World
- Emergence of the “Modern” notebook
- Bridging the gap
- The Subtle Integration of Advanced Features
- Looking Ahead: The Future of Data Science Environments
Share this article:
Introduction to Notebooks
The inception of interactive computational notebooks can be traced back to the 1980s with the development of Maple, Mathematica, and SageMath. These early versions were predominantly academic tools, designed to facilitate computational teaching and learning through a mix of code, visualizations, and narrative text. Mathematica's notebook interface inspired a new way of interactive computing, setting the stage for future developments. Fernando Pérez, deeply influenced by his experiences with Mathematica, initiated the development of IPython in 2001, laying the groundwork for what would become a significant shift in data science tools.

Transition from Academia to Business
By 2007, the IPython team embarked on creating a notebook system, integrating text, calculations, and visualizations. This effort culminated in the release of the first version in 2011. The transformation of IPython into Project Jupyter in 2014 marked a pivotal moment, splitting the notebook functionality into a separate project. Jupyter's single kernel system design allowed it to serve a broad spectrum of scientific and research applications. Early data scientists, transitioning from academia, adopted Jupyter for its flexibility and interactive capabilities, despite its limitations for production environments.

Evolution within the Corporate World
The evolution of Jupyter notebooks was significantly influenced by the open-source movement, with pivotal contributions like SciPy and Matplotlib laying the foundation for Python's scientific computing capabilities. These developments, coupled with Jupyter's ability to share and collaborate on python projects easily, highlighted its utility in academic and professional settings. However, the growing demand within the corporate world for projects to go beyond the exploratory limitations of a notebook meant that, in order to attempt to get their work into production, data scientists needed to move into some sort of IDE once they had completed their exploratory data analysis inside of a notebook. This often involved handing their work over to another data practitioner, such as a data engineer or MLops engineer, who would likely need to re-code the work in an IDE. The origins of this problem can be seen in the un-reproducibility of research and data scientists coming from academia into the corporate world brought this reproducibility problem with them by bringing in the tooling they already knew.
Emergence of the “Modern” notebook
Following this evolution within the corporate world, a new era of notebooks began to take shape. Cloud-based platforms such as Google Colabemerged, building upon Jupyter's foundational, single kernel architecture. These platforms attempt to modernise the data science development journey, with enhanced collaborative and interactive features. However, they are still in essence forks of the original Jupyter notebook and therefore pose the same problems when it comes to deployment.
Bridging the gap
What has become clear is that as the field of data science has matured, the limitations of notebooks have become apparent. They are excellent for exploration and visualization but less suited for more extensive software development or production-level code. This led to a gap between the exploratory work done in notebooks and the development work done in traditional Integrated Development Environments (IDEs). Why this gap is more important today than ever before is because the world is demanding that AI and models make it into production. This gap is where Zerve, a unified developer space for data science & AI, was born. Zerve blends the exploratory flexibility of notebooks with the robustness and scalability of IDEs, enabled by its novel underlying architecture.
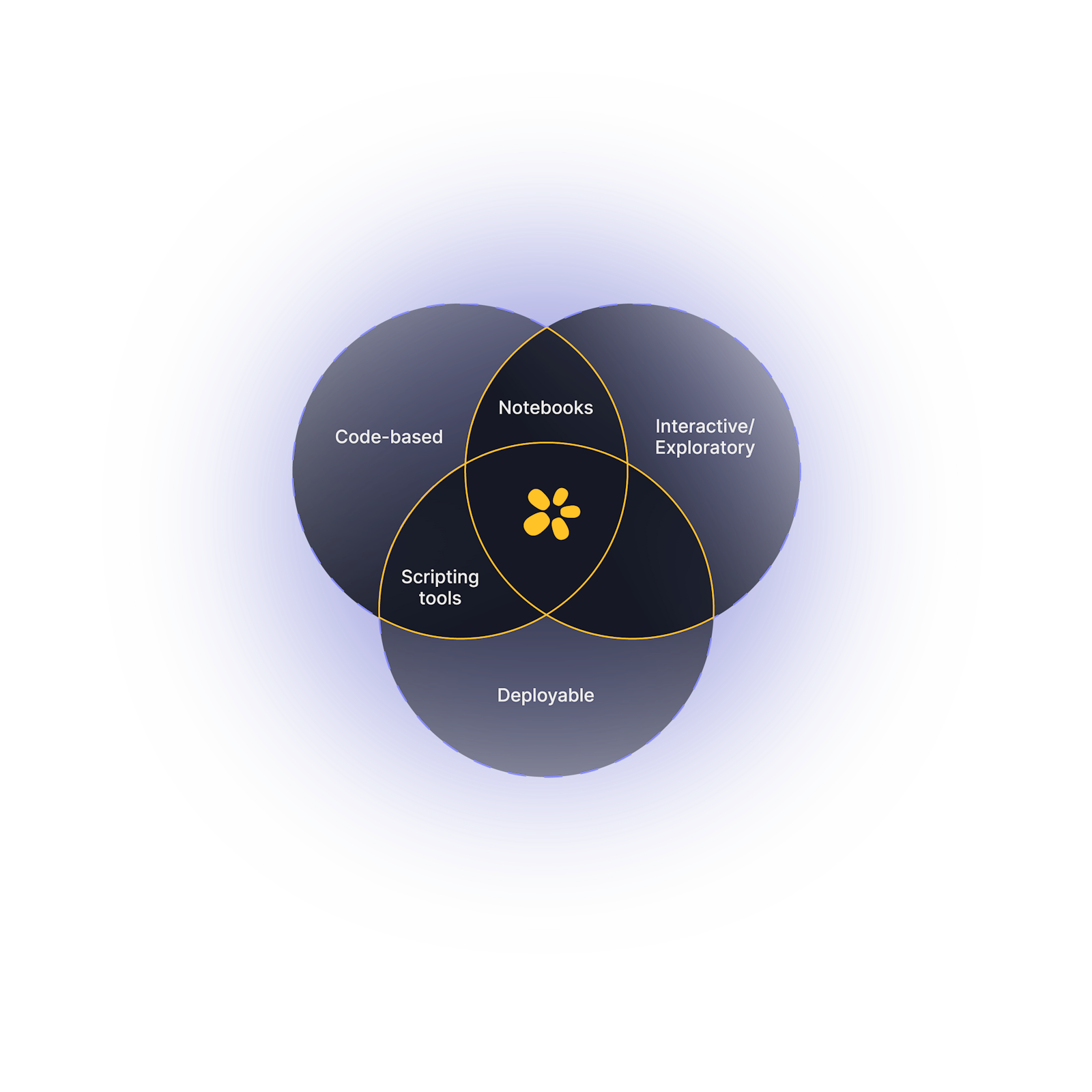
The Subtle Integration of Advanced Features
With this novel architecture comes new benefits like language interoperability, parallelization capabilities, and cloud compute optimization. Such features represent the natural progression of data science development, addressing the growing demands for efficiency and collaboration in the field.
Looking Ahead: The Future of Data Science Environments
The progression of data science environments will be shaped by the burgeoning need for organizations to harness AI, including LLMs and generative AI. This necessitates an efficient development process, where data science and AI teams can minimize their time to value and optimize the path from ideation to deployment. The evolution toward environments that integrate these advanced capabilities more deeply, support seamless collaboration, and enhance both development and deployment stages is crucial in meeting the escalating demands for leveraging AI technologies effectively.
Published: February 29, 2024
Written by: Greg Michaelson
Subscribe to our newsletter: